The advancement in scientific applications and experiments hosted by SESAME infrastructure that depends intensively on computing resources for efficiently delivering their services, makes it more critical now than ever porting the scientific computing to the cutting-edge techniques for performing large-scale experiments. This concern, however, relies on allocating a massive number of computing resources in a fair and efficient manner to cut down the computational complexity into a reasonable time/cost frame. Traditionally, this had been addressed with dedicated high-performance computing infrastructures (i.e., supercomputers) and Cloud configurations by relying on a network of instances, potentially extended all over Southeast Europe and Eastern Mediterranean.
Yet resource management is always a significant challenge to avail all the demanded services of the scientific applications consumers besides the associated difficulty to setup, maintain, and operate these platforms at various computing areas. To this end, and aiming at dynamically exploiting the existing infrastructure, SESAME prototyped a container-based cluster to be deployed on top of any installed infrastructure. The proposed solution supports tasks execution in a pilot-job abstraction and dynamically shares VI-SEEM capabilities, i.e., computing power, network, and storage. Therefore, it unifies and facilitates access to increasingly heterogeneous resources over geo-distributed locations in a single pool of resources.
The project by Feras M. Awaysheh in collaboration with the VI-SEEM members SESAME/Jordan, attempts to serve as interoperability layer for allocating and managing resources, besides enhancing the overall utilization of the VI-SEEM infrastructure and regional resources. It also couples new data analytics frameworks and algorithms to the VI-SEEM bag of solutions. In addition, it ports new methods of processing the generated data from SESAME scientific experiments. As for using MapReduce, Apache Spark, and the Hadoop stack technologies in solving protein structure, µ images reconstruction, and 3D volume µ image data analysis for both macromolecular crystallography (MX) and µ- Tomography beamlines, it is shortly expected to contribute to the project under an open source policy in the Clowder repository.
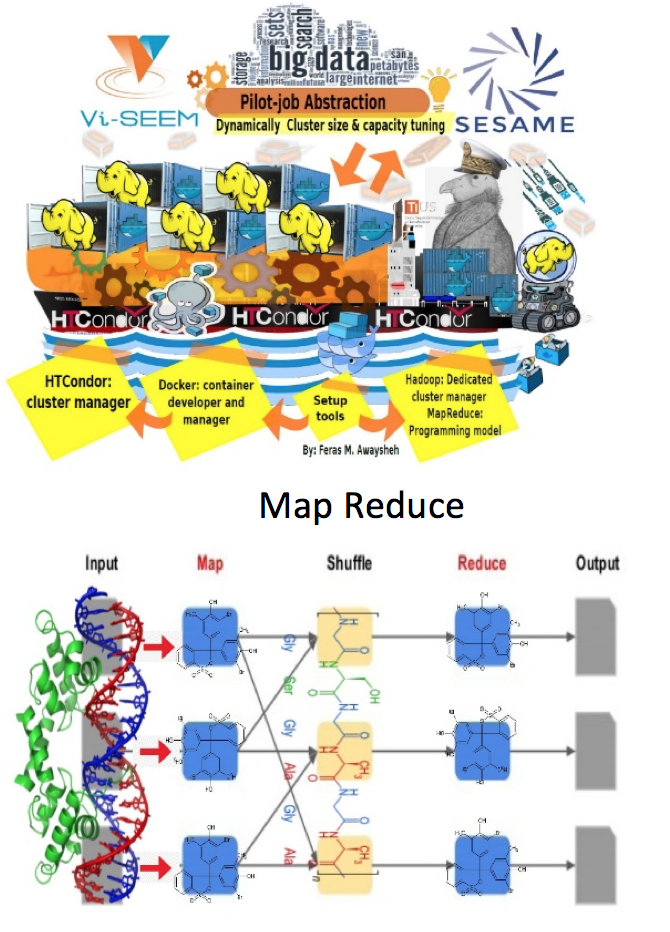
Map Reduce
SESAME, Jordan: http://sesame.org.jo/sesame_2018/